Data Profiling
Data Profiling Introduction
Blindata’s Data Profiling Framework is SQL-based, which offers several advantages over other methods:
- Extreme Personalization: The profiling Metrics are customizable and extendable in order to meet specific needs and preferences. SQL queries can be used to define and calculate any Metric that is relevant for data quality, such as completeness, validity, accuracy, consistency, timeliness, uniqueness, or cardinality. SQL functions enable to perform complex transformations, aggregations, or validations on data.
- Preserved confidentiality: SQL expressions anonymize or exclude any data whose aggregates or metrics that may disclose confidential information, such revenues, wages and other confidential datasets. This protects sensitive or confidential data from unauthorized viewer or any form of exposure.
- Costs saving: SQL commands take advantage of the existing computational capacity and resources, such as databases and systems, without moving or copying any data. This avoids additional network costs, prevents latency issues and data duplication and preserves the confidentiality and integrity of data, by minimizing the risk of data breaches or corruption.
Data Profiling Framework Structure
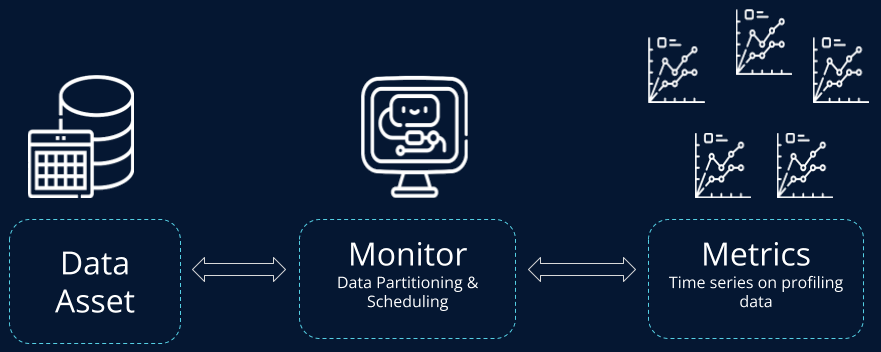
The Data Profiling Framework is based on Monitors and Metrics ( a detailed definition can be found here ).
Starting from a single data asset ( e.g. Physical Entity), it is possible to define one or more Monitors. A Monitor serves both to schedule the execution of a profiling SQL query and to define data partitioning logics, for specifying which data of the Physical Entity needs to be profiled.
A Monitor contains a set of profiling Metrics, representing various profiling data collected by the Monitor during its executions. In a more pragmatic sense, each Metric is a series of data collected over time.