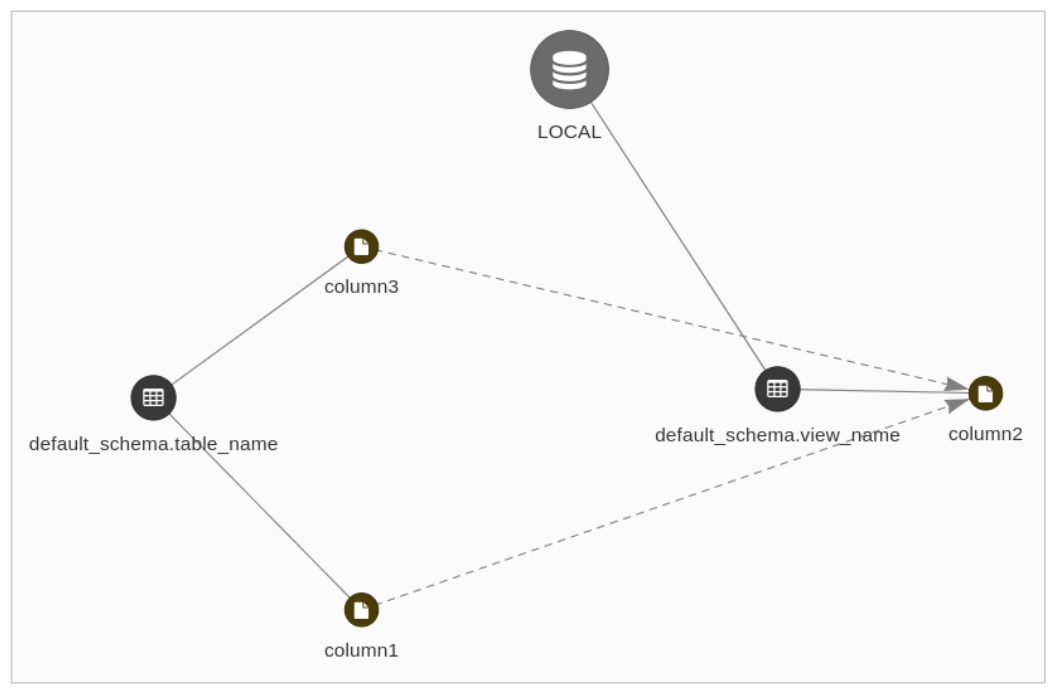
Analyze SQL statements
What is a Query Bucket?
A Bucket is defined to group a set of Statements. To each Bucket is defined a list of systems through which it is generated the Catalog, used by Parser. A Bucket is configurable to automatically generate DataFlow from Statements which are inserted inside of it. In addition, it contains pre-processing settings which allow you to substitute portions of text of SQL statements using regular expressions. This is useful in the case in which there would be Statements based on SQL dialects not completely supported by Parser.
Bucket statistics are calculated on the basis of the inside of Statements status. The percentage of a Bucket completion is calculated considering the Statements overall on those that still need user intervention (indicated with “pending”, including ANALYZED and PARTIALLY_ANALYZED status). Statistics are viewed both on Bucket list and detail page.
How to create a Query Bucket
It is possible to add a new Bucket going in the subsection “query parser” of the section “data flow”.
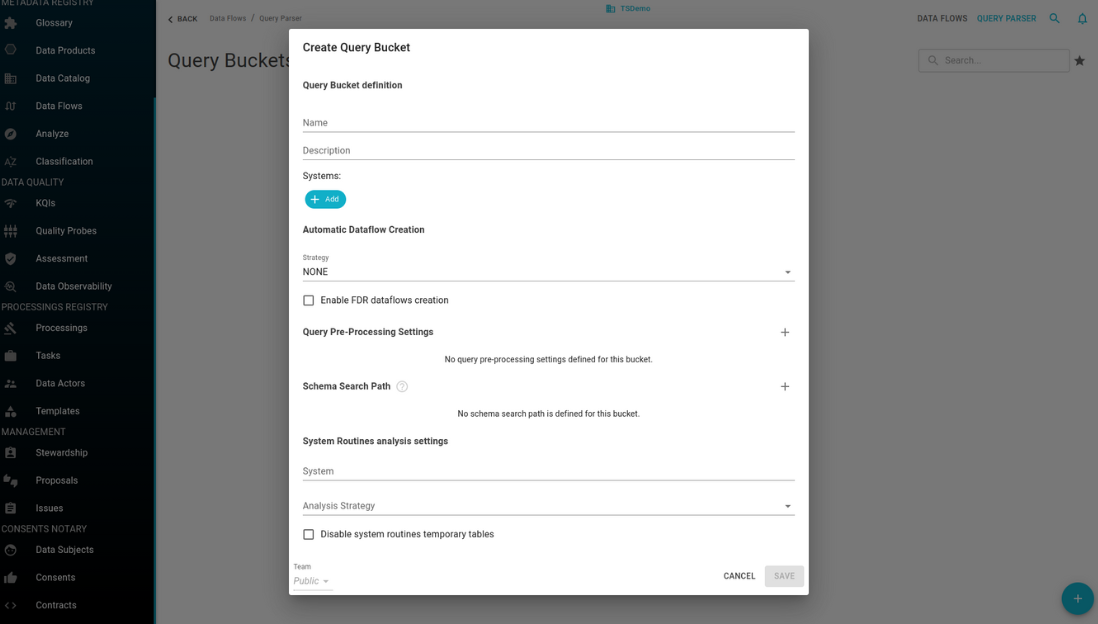
General configurations
- Name: (mandatory) the unique name for this bucket.
- Description: a description of the bucket and its intended usage.
- Systems:The list of systems whose tables are referenced by the bucket’s statements is essential for loading metadata from the data catalog. Accurate metadata is crucial for properly analyzing the query statements. If the systems configuration is incorrect, it may lead to incomplete analysis of the statements, causing them to be in the partially analyzed state.
- Schema Search Path: in a statement, the table schema can be:
- Explicit, e.g. using the syntax « schema name ».« table name ».
- Implicit, where only the table name is present. In this case, the parser will use the default schema stored in the query statement to search the table inside the configured systems. If the default schema can be more than one, the additional schemas can be added in the “schema search path” configuration. P.A. the order of declaration gives the schema priority during the table search (from top to bottom).
- Query Pre-Processing Settings: these settings can be used to exclude or replace words used in specific SQL syntax that are not supported by the statement parser, using regular expressions to perform the matches.
- Team: the team to which the Bucket is assigned.
Data flow generation configurations
-
Strategy: the strategy for the automatic creation of DataFlows, which can be:
- No one: the automatic generation is disabled.
- At Physical Entity level: the generated data flows will be from tables to tables.
- At Physical Fields level: the generated data flows will be from tables columns to tables columns.
-
Enable FDR data flows: there can be two types of data flows:
-
FDD (From Data to Data) Relation: Definition: Indicates that the data in the target column comes directly from the source column. Example: In the SQL query SELECT a.empName “eName” FROM scott.emp a, the column “eName” in the result set is sourced from the empName column of the scott.emp table. This establishes a dataflow relation like scott.emp.empName -> fdd -> “eName”.
-
FDR (From Data to Rows) Relation: Definition: Indicates that the data in the source column affects either the number of rows in the result set or the result of an aggregate function. Example: In the SQL query SELECT a.empName “eName” FROM scott.emp a WHERE sal > 1000, the number of rows in the result set depends on the values in the sal column due to the WHERE clause. This establishes a dataflow relation where the data in the sal column impacts the result set.
In essence, FDD shows how data flows from source to target columns, while FDR shows how source data affects the result set’s size or aggregate results. FDR data flows generation is disabled by default. To enable it, select the checkbox in the configuration.
-
System routines analysis configuration
The configurations for the analysis of system routines can be found under “system routines analysis settings”. Here it is possible to configure:
- System: the system from which the routines will be automatically analyzed after each creation or modification.
- Analysis Strategy:
- Automatic: the statements contained inside the routines will be automatically detected, analyzed and stored in the query bucket.
- Markup: the statements are extracted from the routines using a custom markup annotations on the routines body.
- Disable temporary tables: by default, when a routine includes DDL statements, the parser generates temporary tables from these statements. In addition to the data catalog tables, these temporary tables help analyze other SQL statements within the routine and compute the data lineage. This behavior can be disabled by clicking on the checkbox, so only the data catalog tables are used.
Statement Analysis
A SQL statement is analyzed in order to reconstruct the Lineage which it creates. From Lineage it is possible to extract DataFlow. Thanks to overall saved DataFlow you can trace the data lineage of the entire system. A Statement is analyzed by Parser when this is inserted inside a Bucket or when the text of the SQL statement is modified.
A Statement can have one of the following status:
| Statement State | Description |
|---|---|
| PENDING | Statement must still be analyzed by Parser. |
| ANALYZED | The parser was able to correctly analyze all the Statements and to recover from Catalog all tables used inside a SQL statement. |
| PARTIALLY_ANALYZED | The parser was able to correctly analyze all Statements but it failed to recover from Catalog all tables used inside SQL statements. |
| ERROR | The parser was unable to properly analyze the Statement due to a syntax error in the SQL statement or an error in the analysis. |
| IGNORE | The Statement will not be reviewed by the system. The Statement can be put in this state as a result of an user’s action or a submission of a Statement that however led to the same result as the one produced by another statement. |
| CONFIRMED | One or more DataFlows were generated using the Statement. Once the Statement is in this state, it will no longer be reanalyzed. |
If the Statement is in the ANALYZED or PARTIALLY_ANALYZED status, it is indicated in the field “type” even the type of SQL statement that the Parser was able to recognise.
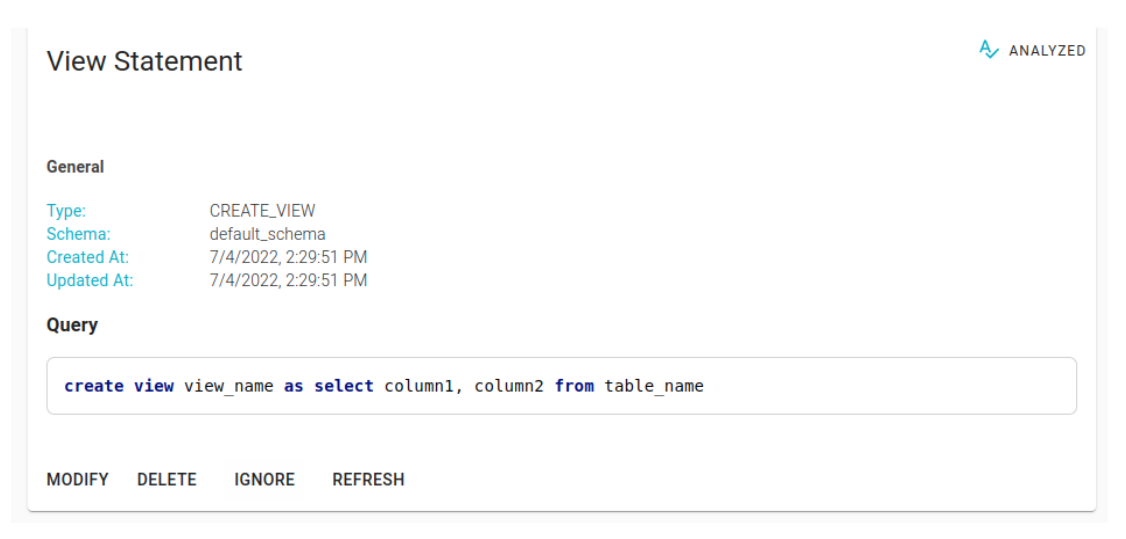
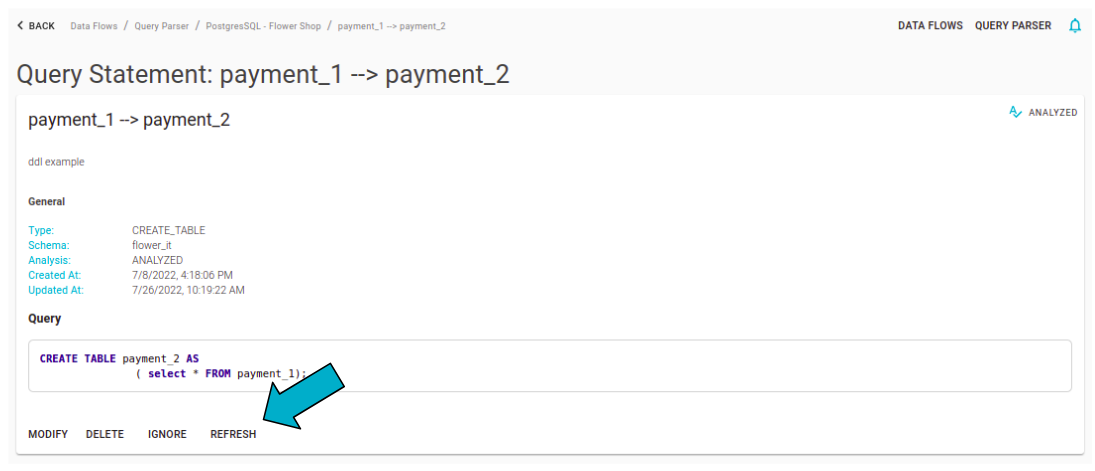
Using the refresh button on the Statement detail page, it is possible to re-analyze it regardless of the state in which it is located (except for a Statement of SELECT or SELECT_INTO which has been linked to a target table).
Target destination of a select statement
An entity in a system may have been generated from data in another system. If extraction is done using a SQL statement , it is possible to represent this link connecting to a SQL statement of SELECT with a target table outside the system. Every time that a SELECT Statement is correctly analyzed by Parser ( ANALYZED o PARTIALLY_ANALYZED status), it is shown a warning with a button that refers to a modal for the link with a target table.
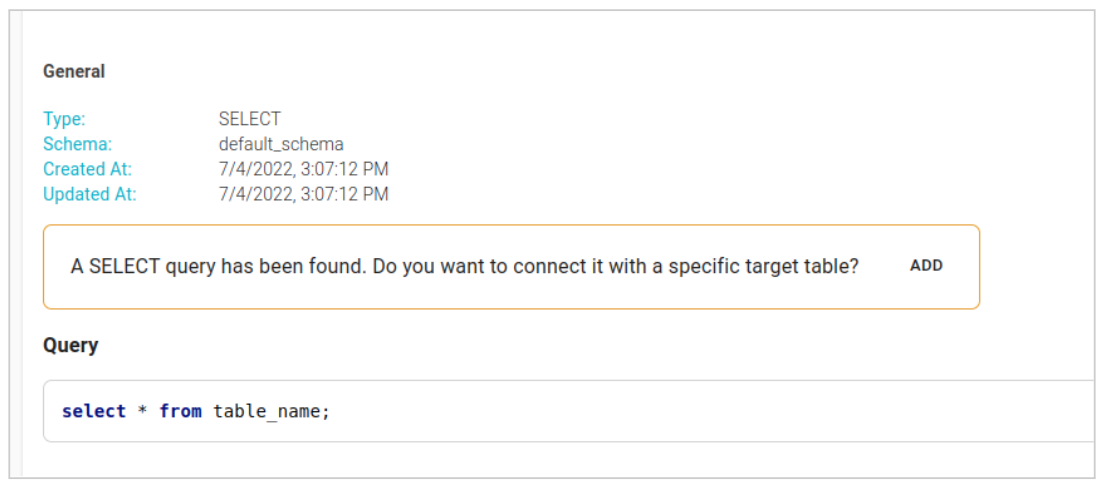
From modal it is possible to choose the target table among the Physical Entities.

You can then connect the output of the SQL statement with Physical Fields of target table through:
- Column number
- Index number of the column.
- Choosing by hand the Physical Field.
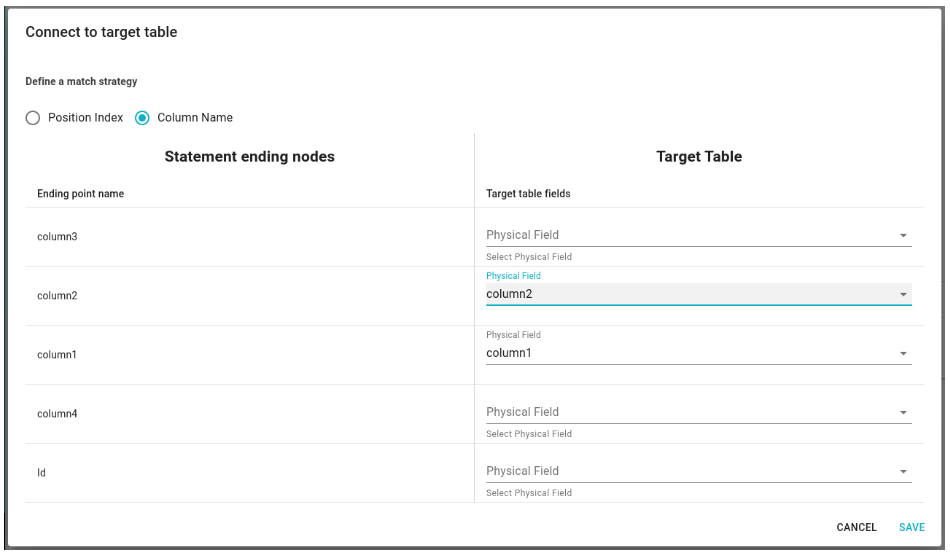
Once the table is connected the lineage is updated and it is possible to generate the related DataFlows.
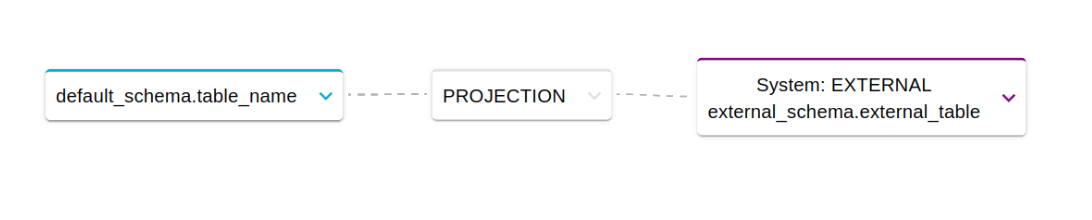
Lineage between entity not involved in SQL statements
An entity in a system may have been imported from another system without using SQL statements (e.g. dump csv, file transfer, job of etl). In this case, a link between two Physical Entities is represented through or a single DataFlow, or a set of DataFlows between their Physical Fields. To generate the DataFlow simply go to the detail page of one of the two Physical Entities and access the section dedicated to DataFlows.
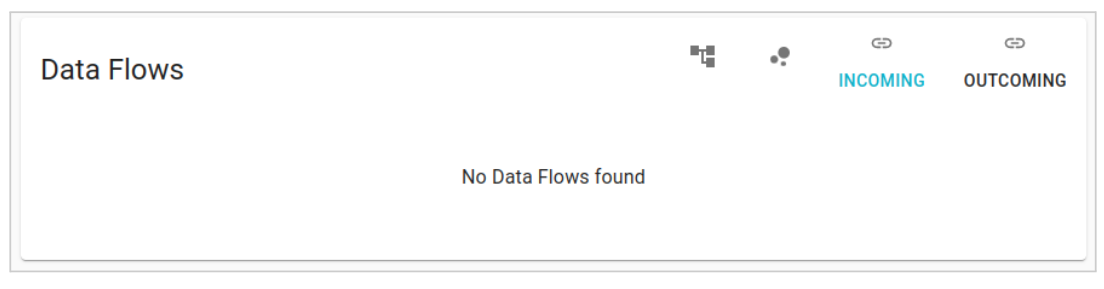
From here then to establish the direction of the connection one of the two icons located above the buttons must be selected “INCOMING” and “OUTCOMING”. These open a modal, by which you can choose the connection level (a single DataFlow between the two Physical Entities or more DataFlow between their Physical Fields).

If it is chosen the link at Physical Fields level, DataFlows can be generated using two different strategies:
- Through Ordinal Position of Physical Fields.
- Through Column Name of Physical Fields.
Finally, there is always the possibility to manually choose individual links between fields.
Dataflow creation strategies
Once the Parser has managed to extract the Lineage from a Statement, the data lineage information can be saved within the data catalog through the DataFlows.
Starting from a Statement it is possible to generate DataFlows, if the following conditions are satisfied:
- Statement’s status is ANALYZED or PARTIALLY_ANALYZED.
- The starting Physical Entity and target Physical Entity are inside the catalog.
- The Lineage obtained from the analysis of the Statement contains at least one path between the source Physical Entity and the destination one.
Creation can be either manual or automated:
| Strategy | Description |
|---|---|
| Manual creation of Dataflows | In order to create a DataFlow manually you need to go to the “Data Flows Preview” section on the Statement’s detail page. Here, a list of all the DataFlow previews that can be generated starting from the analyzed Statement will be shown. Previews are calculated either at the level of Physical Fields or at the level of Physical Entities. 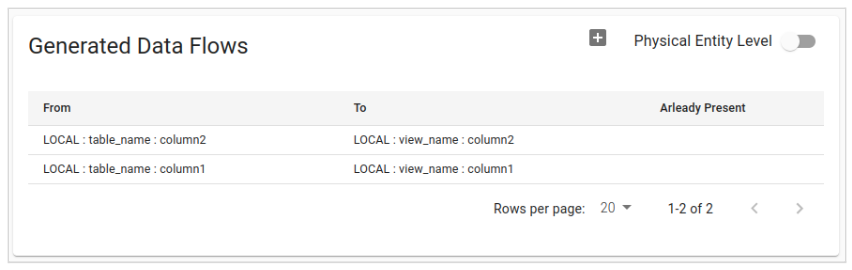 This behavior can be selected via the “Physical Entity Level” switch. To save the previews, just click on the appropriate add button and confirm. Previews that generated DataFlow are indicated with a blue check. |
| Automatic creation | It is possible to create DataFlows at the same time as inserting a new Statement inside a Bucket. This feature can be enabled in the Bucket settings by editing the “Automatic DataFlow Creation’’ items.  As with manual generation, it is possible to choose whether to generate DataFlows at the level of Physical Entities or at the level of Physical Fields. |
Refreshing Statements analysis
The refresh operation allows you to reset the operations performed on the statement and rerun the analysis. This includes deleting dataflows and removing any associated target tables (for select statements). The operations performed during the refresh are as follows:
- rollback and deletion of created dataflows
- deletion of full lineage data
- parsing the statement and generating a new full lineage
- automatic data flow creation if enabled on the bucket
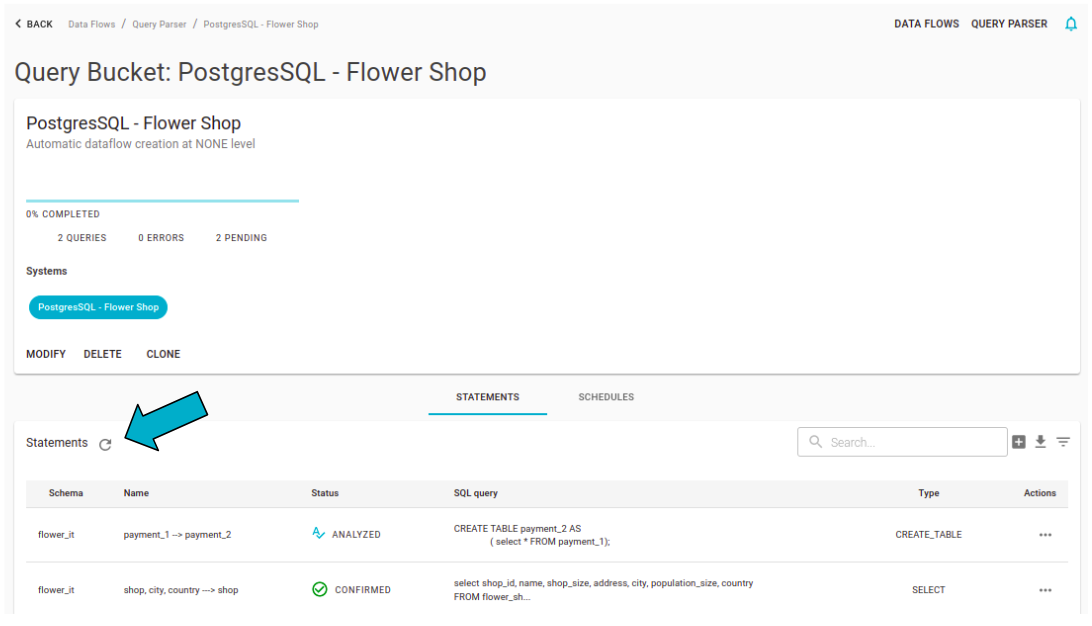
On the detail page of a Bucket it is possible to apply a massive refresh to all the statements it contains. The procedure can take several minutes to complete: it is necessary to keep the application open.
Lineage Visualization
The Lineage can be viewed on the Statement detail page, in the “Full Lineage” section. It is available only in the case of a positive analysis (ANALYZED or PARTIALLY_ANALYZED status).
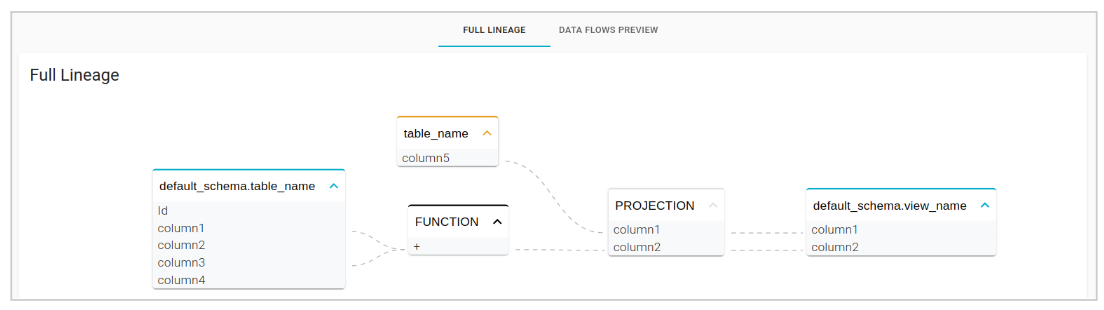 The columns found in the Catalog are grouped by the name of the table they belong to and are shown in blue, while those not found are shown in orange and grouped by the probable names of the tables they belong to.
The columns found in the Catalog are grouped by the name of the table they belong to and are shown in blue, while those not found are shown in orange and grouped by the probable names of the tables they belong to.
The visualization of the complete data lineage is located in the “Data Flows” sub-section of the Physical Entities detail page.

You can choose whether to view the data lineage via flow chart
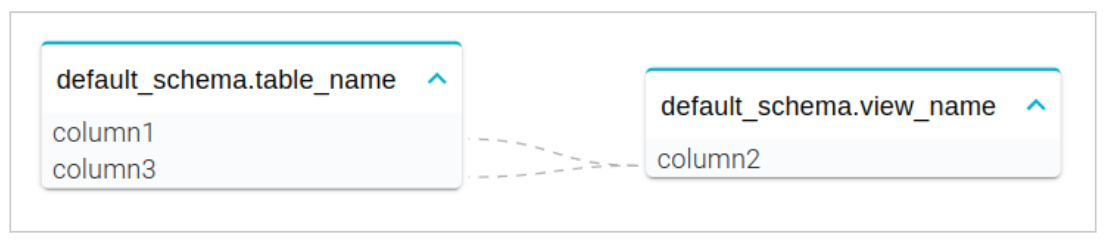 or via graph.
or via graph.