Scheduling SQL Lineage Extraction
Scheduling and statements extraction
By utilizing the scheduling tab within the detailed view of a Query Bucket, you can automate the extraction of statements. It’s important to note that this functionality necessitates the installation of Blindata Agent.
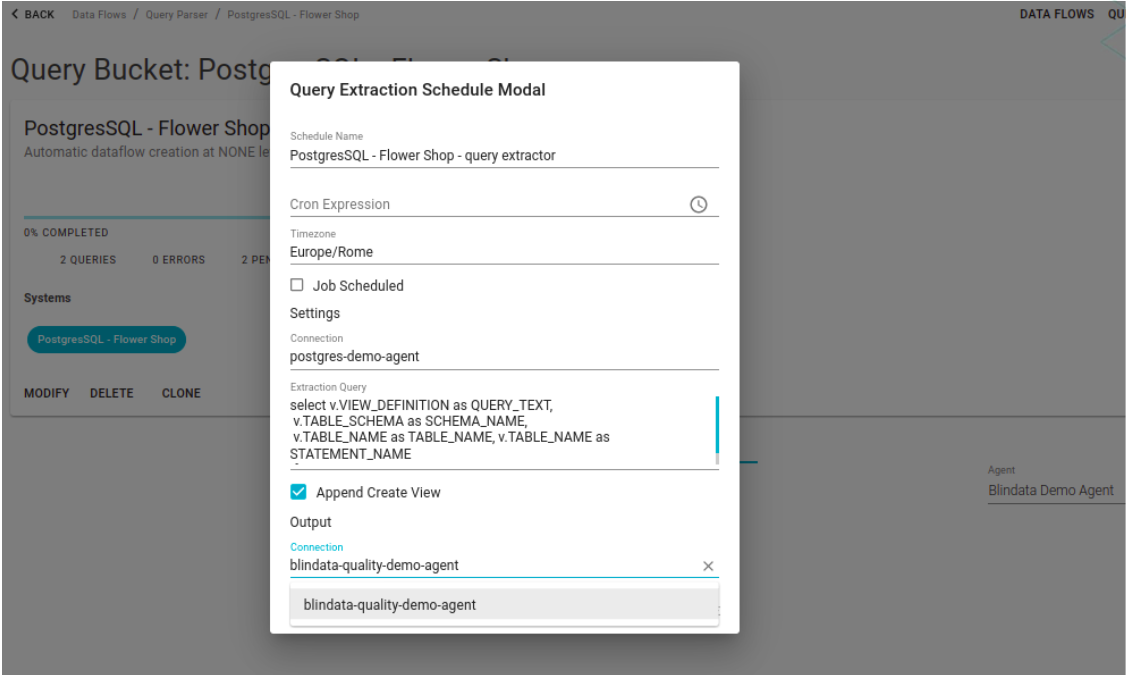
With the definition of an extraction query and the appropriate aliases it is possible to automatically load sql statements for the creation of views or from the query log. The default is set for the extraction of the views from the INFORMATION_SCHEMA, if it is not present, refer to the following paragraphs for the extraction queries on the individual systems. The “Append Create View” flag allows you to reconstruct the view creation statement starting from its select.
Note
To import database routines in Blindata, refer to the database crawling tutorials. To load custom scripts, explore the API or use the CSV importer.
The extraction query allows you to extract not only view definition statements but also statements from query logs or history tables if these are available in the system. In these cases the records must be suitably filtered in order to reduce the noise; for example by filtering for the user who manages the ELT procedures. In these cases the “Append Create View” flag must be disabled.
The aliases needed for the extract query to work are:
| Alias | Description |
|---|---|
| QUERY_TEXT | Represents the text of the sql statement to extract |
| SCHEMA_NAME | Represents the default schema on which the SQL statement was executed |
| TABLE_NAME | Optional if flag “Append create view” set to false. Indicates the name of the table. Create view statements are often only registered through their select. |
| STATEMENT_NAME | The name of the statement that will appear in the interface. |
Tip
In architectures that heavily depend on database routines or scripts for ETL transformations, it is advisable to avoid using query logs. Query logs tend to produce noisy results and are less efficient compared to an analysis performed directly on routines.If using query logs is essential, ensure accuracy by filtering based on the user executing the ETL transformation, specific types of statements, and a carefully selected time window to minimize irrelevant information.
Common database configurations
The following paragraphs provides guides for extracting the Query Logs and DDL Queries. Please use this as an indication on where to look and perform proper configuration and filtering.
Oracle
VIEW DDL EXTRACTION
SELECT
text AS QUERY_TEXT,
owner AS SCHEMA_NAME,
view_name AS TABLE_NAME,
view_name AS STATEMENT_NAME
FROM ALL_VIEWS
WHERE owner IN ('schemaname')
QUERY LOG EXTRACTION
SELECT * FROM v$sql;
Postgresql
VIEW DDL EXTRACTION
Use the default information_schema possibly appropriately filtered for the records of interest.
If views permissions and ownership cause problems with view definitions extraction, the following query should be used instead.
select
v.definition as query_text,
v.schemaname as schema_name,
v.viewname as table_name,
v.viewname as statement_name
from pg_catalog.pg_views v
where schemaname NOT IN ('pg_catalog', 'information_schema','public')
QUERY LOG EXTRACTION
There is no system log query by default. It can be generated to file or extracted with other tools.
Mysql
VIEW DDL EXTRACTION
Use the default information_schema possibly appropriately filtered for the records of interest.
QUERY LOG EXTRACTION
The general_log can be used to extract the history of the statements. Refer to the guide https://dev.mysql.com/doc/refman/8.0/en/log-destinations.html
Vertica
VIEWS DDL EXTRACTION
SELECT view_definition as QUERY_TEXT,
table_schema AS SCHEMA_NAME,
table_name AS TABLE_NAME,
table_name AS STATEMENT_NAME,
FROM v_catalog.views;
QUERY LOG EXTRACTION
There are two tables you can use to extract query history on Vertica clusters:
query_requests
dc_requests_issued
BigQuery
VIEWS DDL EXTRACTION
-- Returns metadata for views in a single dataset or in a region.
SELECT v.VIEW_DEFINITION as QUERY_TEXT,
v.TABLE_SCHEMA as SCHEMA_NAME,
v.TABLE_NAME as TABLE_NAME,
v.TABLE_NAME as STATEMENT_NAME
FROM [PROJECT-ID].[region-EU|myDataset].INFORMATION_SCHEMA.VIEWS v;
QUERY LOG EXTRACTION
The extraction of the history of the statements can be performed using one or more logging tables present in the INFORMATION_SCHEMA.
SELECT
*
FROM
region-us.INFORMATION_SCHEMA.[table]
Where table is one of the following values:
- JOBS_BY_PROJECT
- SESSIONS_BY_USER
- SESSIONS_BY_PROJECT
RedShift
VIEW DDL EXTRACTION
Use the default information_schema possibly appropriately filtered for the records of interest.
If views permissions and ownership cause problems with view definitions extraction, the following query should be used instead.
select
v.definition as query_text,
v.schemaname as schema_name,
v.viewname as table_name,
v.viewname as statement_name
from pg_catalog.pg_views v
where schemaname NOT IN ('pg_catalog', 'information_schema', 'pg_automv','public')
QUERY LOG EXTRACTION
Amazon Redshift has many system tables and views that contain logging information. Between these.
- STL_QUERYTEXT captures the query text of SQL commands.
- STL_QUERY returns execution information on a database query.
The following SQL queries are captured on these two tables.
- SELECT, SELECT INTO
- INSERT, UPDATE, DELETE
- COPY
- UNLOAD
- VACUUM, ANALYZE
- CREATE TABLE AS (CTAS)
STL_QUERY stores a portion of the query text. To rebuild the SQL stored in the text column of STL_QUERYTEXT, execute a SELECT statement to build the SQL from 1 or more parts in the text column. Before running the reconstructed SQL, replace any (\n) special characters with a new line. The results of the following SELECT statement are reconstructed SQL rows in the query_statement field.
WITH query_sql AS (
SELECT
query,
LISTAGG(text) WITHIN GROUP (ORDER BY sequence) AS sql
FROM stl_querytext
GROUP BY 1
)
SELECT
q.query, userid, xid, pid, starttime, endtime,
DATEDIFF(milliseconds, starttime, endtime)/1000.0 AS duration,
TRIM(database) AS database,
(CASE aborted WHEN 1 THEN TRUE ELSE FALSE END) AS aborted,
sql
FROM
stl_query q JOIN query_sql qs ON (q.query = qs.query)
WHERE
endtime between '2018-12-01 00:00:00' and '2018-12-14 00:00:00'
ORDER BY starttime;
Snowflake
VIEWS DDL EXTRACTION
Use the default information_schema possibly appropriately filtered for the records of interest.
QUERY LOG EXTRACTION
SELECT *
FROM SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY
ORDER BY start_time;
Synapse
VIEWS DDL EXTRACTION
Use the available information_schema or the internal catalog.
QUERY LOG EXTRACTION
For a dedicated SQL pool in Azure Synapse Analytics or Analytics Platform System (PDW), use sys.dm_pdw_exec_requests.
select * from sys.dm_pdw_exec_requests
For serverless SQL pool or Microsoft Fabric use sys.dm_exec_requests.
select * from sys.dm_exec_requests