Executing A Classification Task
How to configure a classification task
Using Blindata agent, users execute data classifications tasks by configuring data classification default settings within the system page of the data catalog. These settings are customizable during launch, as elaborated in the subsequent paragraphs.
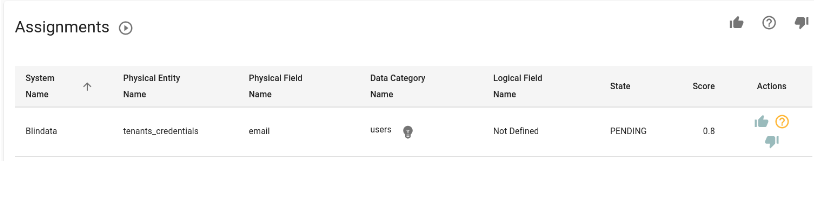
The resultant assignments are displayed in the corresponding assignment table located in the “Classification” panel, under both Physical Entities and Physical Fields.
On the system’s detailed page, users have the capability to set default configurations for job execution.
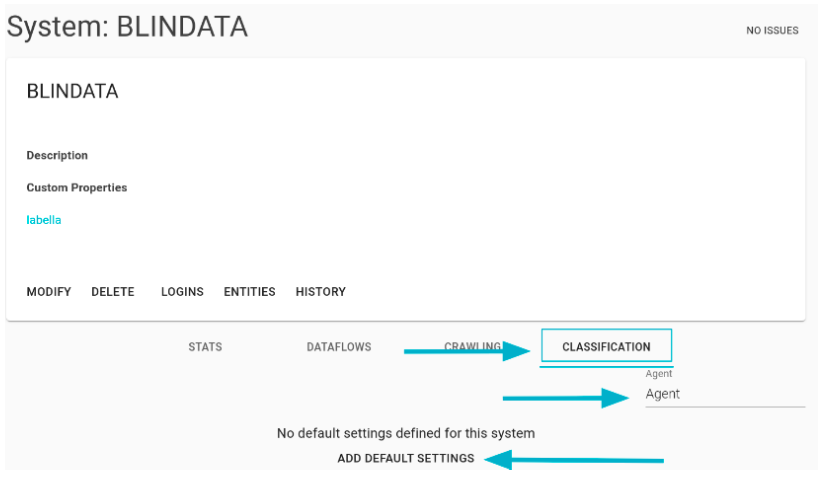
By navigating to the classification tab within the selected system page and clicking on it, users can specify the essential settings for job execution. The necessary configuration fields include:
- Connection: This initial connection determines the source for extracting samples.
- Tables Query: The query for the tabular extraction of samples.
- Columns Query: The query for extracting columns in case the tabular extraction yields insufficient samples.
- Samples: The required threshold of samples, beyond which columnar extraction is not initiated.
- Dictionary Connection: The connection for extracting dictionaries, which may differ from the connection for sample extraction.
- Dictionaries Scopes: Tags utilized for selecting dictionaries.
- Rules Scopes: Tags employed for selecting rules.
- Output Connection: The connection to Blindata where the obtained results will be uploaded.
Tip
It is crucial to acknowledge that the quantity of samples can significantly impact extraction execution times. Specifically, columnar extraction tends to require more time compared to tabular extraction.
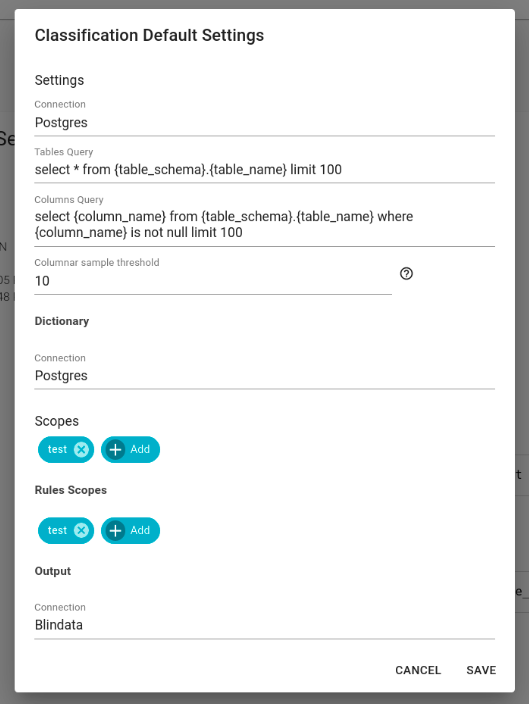
Blindata comes pre-equipped with sample extraction queries as examples. The default configuration will be presented before job execution, providing the option to modify it as needed before initiating the launch.
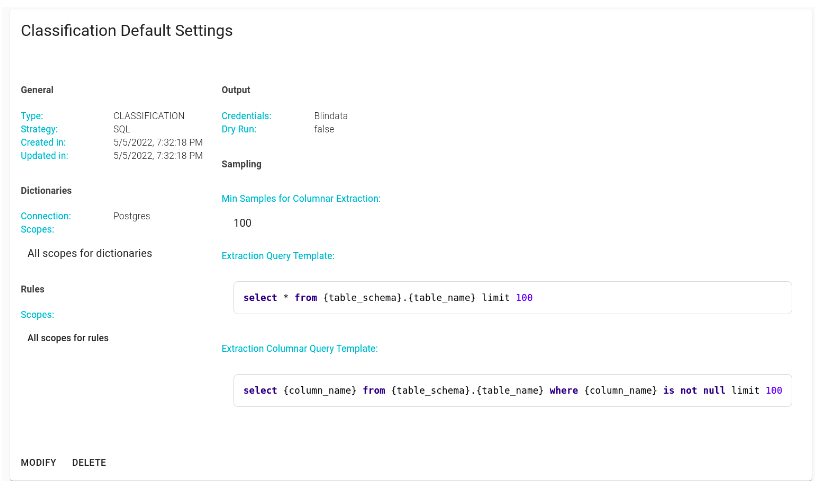
After defining all the specified fields, the “Classification” panel within the system will showcase the settings created. Users will have the option to either modify or entirely cancel these configurations as needed.
How to launch a classification task
Once the default settings have been set, within the tables and fields of the system, under the “Classification” tab, a play button will be displayed next to the panel’s title.
Clicking this button opens a form where users can review the defined settings or proceed with the execution.
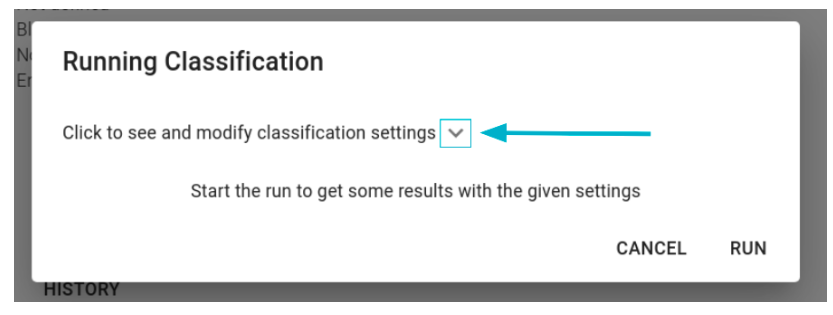
By clicking the arrow depicted in the figure, the window will display the current settings, providing the option to modify them specifically for the upcoming run (without affecting permanent configurations).
Upon initiating the job, results will promptly appear in the table below, as illustrated in the figure.
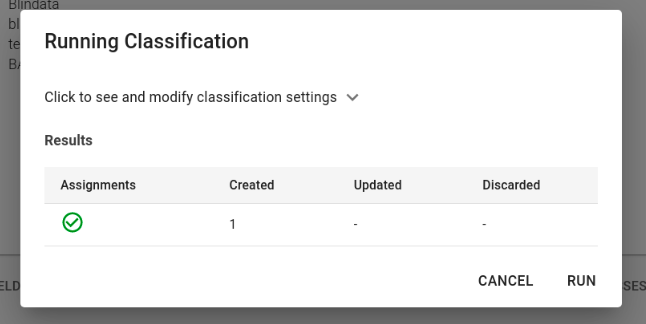
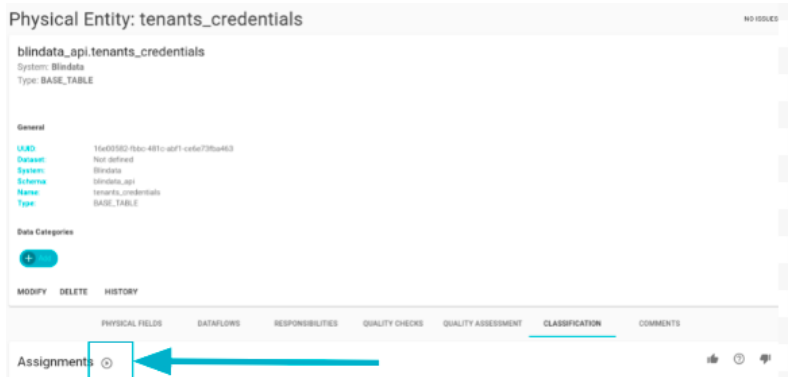
In the assignment panel, users can scrutinize detailed information regarding the number of rows created, discarded, or updated during the execution. Upon completion, the job automatically updates the table, presenting the results in the “Assignments” table of the pertinent physical entity, as depicted in the figure.
How to configure and schedule a massive classification scan
To configure a massive scan you need to provide the job configuration manually. To create a classification job manually, navigate to Settings → Agents → Schedules and then click on the FAB button to launch the job definition modal.
There are two options to select the tables and fields to scan:
- using sql queries: this is the suggested option for performance and flexibility
- using blindata data catalog api
In the next paragraphs you can find two example of such configurations.
Classification configuration based on SQL queries
{
"strategy": "SQL",
"sampling": {
"connectionName": "local-pg-15",
"extractionQueryTemplate": "select * from {table_schema}.{table_name} limit 100",
"minSampleSizeThreshold": 100,
"extractionQueryColumnarTemplate": "select {column_name} from {table_schema}.{table_name} where {column_name} is not null limit 100"
},
"rules": {
"scopes": []
},
"dictionaries": {
"connectionName": "local-pg-15",
"scopes": []
},
"outputOptions": {
"dryRun": false,
"targetConnectionName": "blindata-connection"
},
"crawling": {
"connectionName": "local-pg-15",
"systemUuid": "f7b20aae-7236-492c-9b5e-88e532cf2ceb",
"systemName": "Blindata Postgres",
"queryAllTables": "SELECT table_schema, table_name, obj_description(oid, 'pg_class') AS DESCRIPTION, table_type FROM pg_catalog.pg_class JOIN information_schema.tables ON pg_class.relname = tables.table_name WHERE table_schema NOT IN ('pg_catalog', 'information_schema');",
"queryAllColumns": "SELECT cols.table_schema, cols.table_name, cols.column_name, cols.data_type, pgd.description AS DESCRIPTION FROM information_schema.columns AS cols LEFT JOIN pg_catalog.pg_description AS pgd ON pgd.objsubid = cols.ordinal_position AND pgd.objoid = ( SELECT c.oid FROM pg_catalog.pg_class c WHERE c.relname = cols.table_name AND c.relnamespace = ( SELECT n.oid FROM pg_catalog.pg_namespace n WHERE n.nspname = cols.table_schema ) ) WHERE cols.table_schema NOT IN ('pg_catalog', 'information_schema');"
}
}
Note
The queries in this configuration rely on PostgreSQL. They retrieve comments on tables and fields, which serve as descriptions to be analyzed against the REGEX_TABLE_DESCRIPTION_METADATA and REGEX_FIELD_DESCRIPTION_METADATA rules.
Classification configuration on Blindata Data Catalog API
{
"strategy": "SQL",
"sampling": {
"connectionName": "local-pg-15",
"extractionQueryTemplate": "select * from {table_schema}.{table_name} limit 100",
"minSampleSizeThreshold": 100,
"extractionQueryColumnarTemplate": "select {column_name} from {table_schema}.{table_name} where {column_name} is not null limit 100"
},
"rules": {
"scopes": []
},
"dictionaries": {
"connectionName": "local-pg-15",
"scopes": []
},
"outputOptions": {
"dryRun": false,
"targetConnectionName": "blindata-connection"
},
"crawling": {
"systemUuid": "69c4dade-2222-4cd1-8d2a-7e750b0696ca"
}
}